Agent 的三大模块(一)——记忆 Memory

Agent 的三大模块(一)——记忆 Memory
xiaoye记忆——Memory
Agent 的记忆分为短期记忆和长期记忆。
短期记忆(Short-Term Memory),也称为工作记忆,即最近即时上下文的缓冲区,包括 Agent 最近的行动。
然而 Agent 的执行可能还会涉及多个子任务步骤的执行、多轮工具的调用,短期记忆并不能满足记忆这么多步骤。这就需要长期记忆(Long-Term Memory),来让 Agent 记住数十甚至数百个执行步骤。

如何实现短期记忆
LLM 都有一个上下文窗口(context window),代表了这个 LLM 能够处理的 token 数量。content window通常至少为 8192 个 token,有时可以扩展到数十万个 token。
短期记忆实际上并不是真正让模型记住对话,而是将完整的对话历史作为 prompt 的一部分,和当前问题一起输入进大模型中,来让大模型获取到之前的对话。如果对话历史的 token < LLM 的 Content Window,那么就可以有效模拟记忆。

对于对话历史过大,或者模型本身的 content window 太小的时候,我们可以接入另一个总结 LLM 来总结迄今为止发生的对话,再输入到 Prompt 里面去。
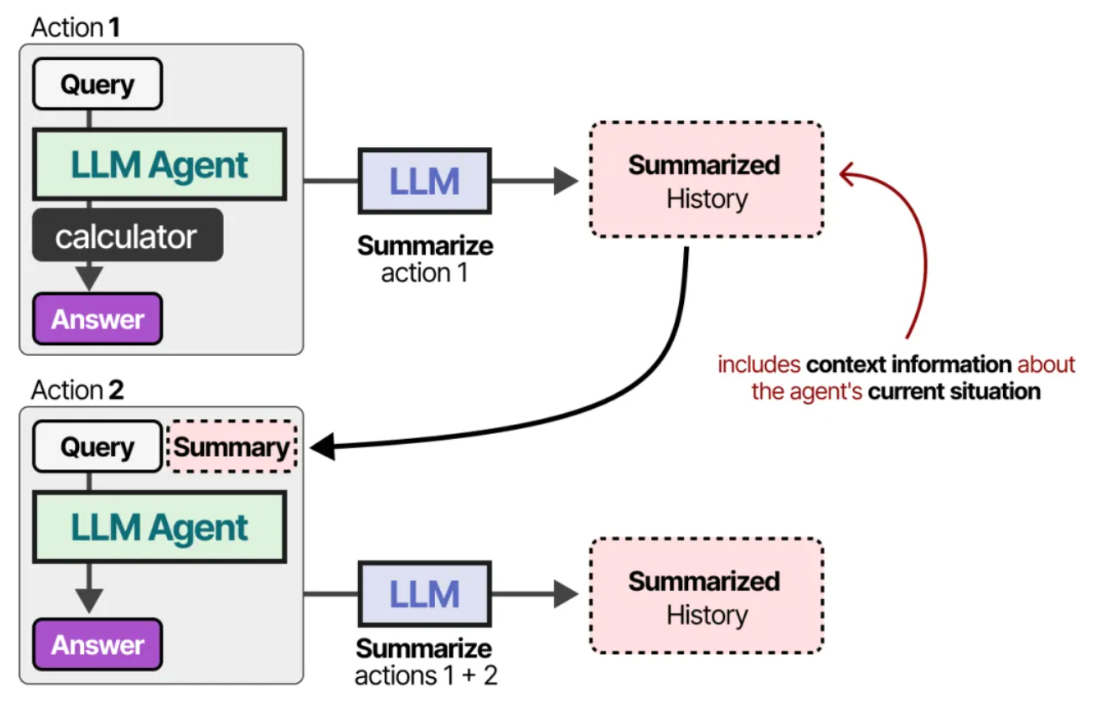
通过持续总结对话,我们可以保持较小的对话规模。这将减少 token 数量,同时只跟踪最重要的信息。
如何实现长期记忆——RAG
LLM Agent 的长期记忆不止包括一些对话的历史内容,它指的是 Agent 过去所有的操作、决策和互动记录等等,而不仅仅是静态的数据或信息。
实现长期记忆的常见技术是将所有先前的交互、行动和对话存储在外部向量数据库(Vector database)中。
怎么构建这个向量数据库呢?我们需要用到 嵌入模型(Embedding Model) 来将对话信息、决策记录、训练数据等等转化为固定长度的向量来表示,比如单词“猫”被向量化为[0.5, 0.2, 0.1],“狗”被向量化为[0.4, 0.2, 0.3]。在这个向量空间中,尽管具体数字不同,但“猫”和“狗”的向量相对更近,因为它们都是动物。

拥有了这个充满知识的向量数据库后,当用户再次输入任何问题,我们都可以继续通过
Embedding Model 将用户问题向量化,并在数据库中查找出和用户问题向量最相关的向量(通常利用计算余弦相似度或其他相似度量来完成)。查找出来的相关向量数据会作为 prompt 的一部分,和新一次的用户问题一起输入给 Agent 处理。
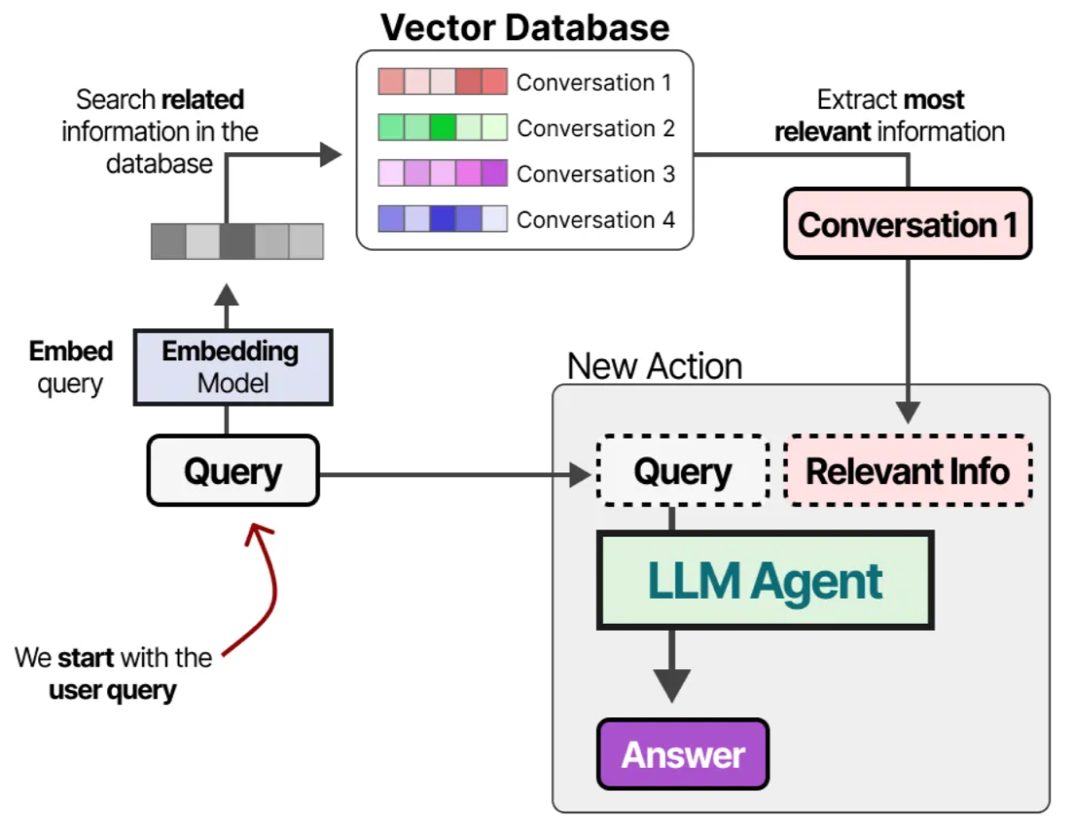
这种方法也就是检索增强生成(Retrieval-Augmented Generation, RAG)。至于 RAG 详细的实现细节,以及 Embedding Model 具体是如何工作的,之后再详细讲解。
《Cognitive Architectures for Language Agents》将4种人类记忆的类型与 LLM Agent 相关联:

1. Working Memory(工作记忆)->短期记忆
- 人类示例:购物清单。人类大脑用工作记忆来暂时存放、操作当前需要使用的信息,比如你在逛超市时,脑海里记着要买的东西。
- 代理示例:Context(上下文)。在LLM Agent中,工作记忆可以理解为模型在一次对话或推理过程中,需要临时“装载”的上下文信息,用于实时生成回复或执行操作。
2. Procedural Memory(程序性记忆)
- 人类示例:系鞋带。人类的程序性记忆是对“如何做一件事”的技能或步骤的记忆,例如骑自行车、打字等,这些行为一旦学会,就可以相对自动地执行。
- 代理示例:System Prompt(系统提示)。对于LLM Agent而言,“程序性记忆”可以视作模型在执行任务时所依据的固定指令或规则。它规定了模型在面对某些输入时,需要如何去执行、遵循哪些步骤或约束。
3. Semantic Memory(语义记忆)
- 人类示例:狗的品种。语义记忆是关于世界的通用知识、事实和概念,不依赖个人的具体经历,比如知道“巴黎是法国的首都”。
- 代理示例:User Information(用户信息)。对于LLM Agent来说,语义记忆中可以包括用户的偏好、历史对话中的关键信息、外部知识库中的事实等。这些事实类信息是与特定事件无关的通用知识。
4. Episodic Memory(情景记忆)
- 人类示例:7岁生日。情景记忆是对个人经历的记忆,包含时间、地点、人物等具体情境。
- 代理示例:Past Actions(过去行为)。在LLM Agent中,这部分对应代理在与用户或环境交互中所做出的具体操作或决策的历史记录,帮助代理回溯和利用过去的经历来影响当前或未来的决策。
这种区分有助于构建代理框架。语义记忆(关于世界的事实)可能存储在与工作记忆(当前和最近情况)不同的数据库中。




